Complete website downloaden met HTTrack
Het kan soms nuttig zijn een complete website te downloaden. Daarvoor leent de tool HTTrack zich uitstekend. Bezint echter voor je begint, want het zorgt voor een hoop extra dataverkeer bij de aanbieder van de site die je gaat binnenhalen.
Een website downloaden is handig om deze lokaal altijd achter de hand te hebben. In onze moderne contreien speelt dat probleem eigenlijk niet meer. De tijd van inbelmodems en trage, onbetrouwbare verbindingen ligt ver achter ons. Maar als je op vakantie of een werktrip naar verre oorden gaat, is een betrouwbare internetverbinding een heel stuk minder vanzelfsprekend. Dat kan een reden zijn om een bepaalde site die je beslist voor werk of studie nodig hebt qua referentiemateriaal voor vertrek te downloaden.
Een veel interessanter scenario is het downloaden van verweesde, historisch interessante websites met unieke inhoud. Daarvan verdwijnen er steeds meer voorgoed. Bijvoorbeeld omdat de eigenaar ervan komt te overlijden, een hoster oude ‘rommel’ verwijdert enzovoort.
Geschiedenis verdwijnt daarmee beetje bij beetje. Heb jij een specifieke hobby waarvoor je sites gebruikt waarvan je merkt dat er al jarenlang geen aanpassingen meer geweest zijn, dan groeit de kans op onverwacht verdwijnen. Zo’n scenario rechtvaardigt downloaden.
Ideaal voor op nas
Ga in principe niet in het wilde weg actuele en goed bijgehouden websites downloaden. Dat kost de aanbieder een hoop dataverkeer. Bovendien is het gedownloade materiaal dan slechts een snapshot in de tijd en al heel snel achterhaald. Focus op die echt bijzondere sites, of op die enkele keer dat je zo’n snapshot nodig hebt in een internetloos gebied.
Om een site te kunnen downloaden komt de gratis tool – zonder meer een veteraan te noemen die al heel lang meedraait – HTTrack best van pas. Hij is er in een variant voor Linux en Windows. Met name de Linux-variant is erg interessant. Het downloaden van een grote site kan dagen tot soms meer dan een week duren. Snelheden worden namelijk maar al te vaak vanaf de kant van de website gelimiteerd.
Het betekent dat de Windows-variant wat onhandig is, want daarvoor moet je een pc dagen en nachten achter elkaar aan laten staan. Niet alleen zonde van het energieverbruik, maar de kans dat Windows tussen de bedrijven door herstart vanwege een of andere update is ook vrij groot.
Je kunt beter bijvoorbeeld een virtueel Linux-systeem op je NAS installeren (als je die optie hebt), en daar HTTrack op installeren. Dat ding staat meestal toch al 24/7 aan, dus een mooi klusje erbij kost je de kop niet aan extra energieverbruik. Of denk eens aan een Raspberry Pi met een wat ruimer bemeten SD-opslag.
Debian als voorbeeld
Wij gaan aan de slag met de Linux-variant (maar als je Windows gebruikt kun je ook meedoen!), een Debian-machine draaiend als VM op een Synology NAS. Om HTTrack te installeren start je de app Software (klik op Activiteiten linksboven en dan in het geopende dock op de boodschappentas). Klik in het geopende venster op het vergrootglaasje linksboven en tik als zoekterm in ’t daarvoor bestemde veld webhttrack.
Klik op WebHTTrack Website Copier en installeer de tool met behulp van de daarvoor bestemde knop op de geopende pagina. Je kunt de virtuele softwarewinkel weer sluiten.
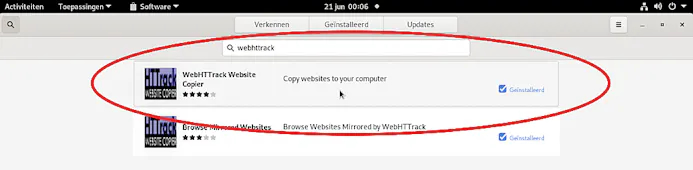
De Linux-versie vind je vervolgens terug in je software-overzicht, in Debian te bereiken met een klik op de veelstippige knop onderaan het dock. Vervolgens wordt je browser gestart. Precies dat is het essentiële verschil tussen de Windows- en Linux-versie. De Windows-versie is een traditioneel .exe-programma, de Linux-variant wordt via een lokale webserver in je browser getoond.
De functionaliteit is echter gelijk, met als enig minpuntje dat de Windowsversie wat ‘gedateerd’ toont qua uiterlijk. Maar het werkt als een tierelier in beide gevallen, en dat is waar het om gaat natuurlijk. Klik op de knop Volgende – rechts onder in beeld – om aan de slag te gaan.
Aan de slag
Als voorbeeld gaan we een kopie trekken van https://www.landley.net. Ga nou niet óók deze site lokaal spiegelen, het is slechts een voorbeeldje. In ieder geval een site met heel veel historische interessante informatie, met name onder Computer History.
Om te beginnen vul je achter Nieuw projectnaam (de Nederlandse taalmodule is niet helemáál foutloos) een omschrijving van je project in. Dat kan – logischerwijs – de naam van de site zijn, met eventueel een keyword waar het om gaat. De overige instellingen kun je in principe laten zoals ze zijn. Klik op Volgende.
Kopieer de URL van de lokaal te spiegelen website en plak deze in het URL-blok. Klik dan op Instellingen definiëren. Er is heel veel mogelijk, hierna adviezen betreffende settings die tot het beste resultaat leiden.
Optimale instellingen
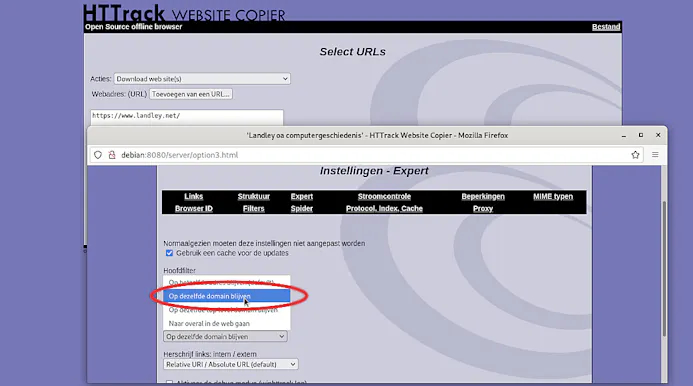
De instellingen onder Links, Struktuur, MIME typen, Browser ID, Filters, Protocol, Index, Cache en Proxy laat je staan op de standaardwaarden. Alleen als je heel specifieke wensen hebt kun je hier wat gaan sleutelen, maar dat zal zelden tot nooit nodig zijn. Gaan we naar Expert. De ervaring leert dat daar de – onder Globale doorloopmodus – de optie Op dezelfde domain blijven vaak betere (lees: completere) resultaten oplevert dan de standaard geselecteerde optie Op hetzelfde adres blijven (default). Krijg je niet de complete site binnen (of juist alleen het deel dat je wilt), dan is dit de plek om even wat te experimenteren.
Let op de maxima
Tik bovenaan op Stroomcontrole, ook hier kun je de instellingen in principe ‘r best zo laten staan als ze zijn. Eventueel kun je het aantal verbindingen achter N# verbindingen iets verhogen. Maakt het spiegelen wellicht iets sneller, maar vormt ook een hogere belasting voor de server waar de site op staat.
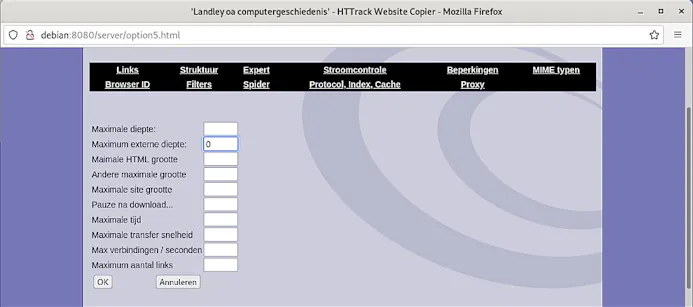
Laten we proberen het een beetje netjes te houden en hier dus niet iets als ‘100’ in te vullen… Klik op Beperkingen en zet hier vooral de optie Maximum externe diepte op 0. Doe je dat niet, dan loop je het risico om ’t complete internet te gaan downloaden. Dat gaat niet alleen lang duren, maar vergt ook – understatement – flink wat lokale opslagruimte.
De Maximale transfersnelheid kun je naar eigen inzicht verhogen, denk aan bijvoorbeeld de helft van je download-bandbreedte die beschikbaar is. Kijk even naar de overige instellingen, wellicht is daar nog iets van je gading te vinden.
Op erg grote en complexe sites is het niet onverstandig om de Maximale diepte ietwat te beperken, tot bijvoorbeeld vijf niveau’s. Daar haal je dan wellicht niet de complete site mee binnen, maar wel de belangrijkste zaken. Scheelt downloadtijd en vooral opslagruimte. Een veld zonder waarde betekent trouwens ‘geen limiet’.
Robot
Veel websites – zo niet alle, tegenwoordig – hebben een tekstbestandje ingebouwd dat aangeeft dat de site niet gekopieerd mag worden door robots. Dit, om te voorkomen dat allerlei automatische tools en crawlers complete sites gaan downloaden en de bandbreedte volledig wordt dichtgetrokken. In principe houdt HTTrack zich ook aan deze regel. Het gevolg laat zich raden: er wordt niks of bijna niks van de site die je wilt kopiëren binnengehaald.
Ofwel: we moeten nu even heel onbeleefd gaan doen en die regel (wens) negeren. Klik daarvoor op Spider en kies onder Volg de regels in Robot.txt de optie Geen robots.txt regels. In principe ben je qua settings nu klaar; klik op OK om alle hierboven gemaakte aanpassingen in een keer door te voeren.

Handige indexpagina
Klik op Volgende en dan Start, waarna het downloaden (lokaal spiegelen) van de site begint. Kan zoals gezegd bij grotere sites een flinke tijd duren, dus erbij blijven zitten heeft meestal weinig nut. Als de spiegeling voltooid is, zie je daarvan vanzelf een melding en kan het browservenster gesloten worden.
Je vindt de site terug in de in de allereerste stap gekozen map, onder Debian is dat standaard de home-map (Persoonlijke map) die bij je Debian-account hoort. Daarin vind je de map websites met de gedownloade sites.
Aardig is dat HTTrack een handige indexpagina maakt. Dubbelklik op het bestand index.html in de map websites en je ziet daar links naar alle onderliggende gedownloade sites verschijnen.