

In dit artikel laten we zien hoe je een AI-chatbot combineert met je eigen documenten om gerichte antwoorden te genereren:
- Leer hoe RAG jouw documenten gebruikt om contextueel relevante antwoorden te geven
- Gebruik NotebookLM van Google voor cloudgebaseerde documentanalyse en samenvattingen
- Installeer en gebruik AnythingLLM lokaal voor volledige controle over je data
- Ontdek alternatieven zoals Ollama en RAGflow voor geavanceerde lokale set-ups
Lees ook: Makkelijk switchen tussen AI-taalmodellen? Maak kennis met Jan
Dit artikel bespreekt oplossingen om eigen documenten als doorzoekbare database aan een AI-model te koppelen, zowel in de cloud (via NotebookLM) als lokaal (met tools als AnythingLLM en Ollama). Bij dit proces haalt een model eerst relevante informatie uit een specifieke externe bron of database op (retrieval) en gebruikt deze vervolgens om een contextueel antwoord te genereren (generation). Dit heet Retrieval-Augmented Generation, kortweg RAG.
Voor we concreet ingaan op de genoemde tools, leggen we kort uit hoe een AI-chatbot je prompts analyseert en op basis van getrainde kennis een relevant antwoord probeert te genereren. Daarna bekijken we hoe dit in een RAG-context verloopt.
1 LLM-dataverwerking
Veel mensen denken dat een AI-model zoals ChatGPT of andere Large Language Models (LLM’s) zoals Gemini, Grok, Llama of Claude bij een prompt direct een database van webpagina’s doorzoekt, een samenvatting maakt en die als antwoord teruggeeft. Afhankelijk van het model en je vraag kan er soms in live internetbronnen worden gezocht, maar doorgaans werkt dit proces fundamenteel anders.
In de trainingsfase leren LLM’s namelijk hoe woorden, zinnen en concepten samenhangen. Deze informatie wordt vervolgens opgesplitst in kleine woorddelen (tokens) en door een embedding-functie opgenomen (ingebed) als miljarden getallen, oftewel parameters, in één- of meerdimensionale tabellen, zoals vectoren en tensors.
Zo kan het woord ‘bank’, afhankelijk van de context, in een andere tabel belanden. Bij ‘Geld op een bank zetten’ wordt ‘bank’ gekoppeld aan financiële begrippen zoals ‘geld’ en ‘spaar’, terwijl ‘bank’ bij ‘Op een bank zitten’ aan huiselijke begrippen als ‘stoel’ en ‘zit’ wordt gelinkt. Deze structuur heet een transformer-model, en vandaar ‘GPT’: Generative Pre-trained Transformer.
Wanneer je nu een prompt invoert, zet de chatbot deze eerst om in vectoren die de contextuele betekenis weergeven. Deze worden vervolgens vergeleken met de LLM-parameters, waarna het model stapsgewijs de meest waarschijnlijke volgende tokens voorspelt. Uiteindelijk wordt deze tokenrij naar woorden omgezet en krijg je als gebruiker een antwoord terug.
De positionering van (een homoniem als) ‘bank’ in deze vector zal ook afhangen van de context.
2 RAG-dataverwerking
Wanneer je zelf databronnen toevoegt, zoals docx- of pdf-bestanden, of zelfs afbeeldingen, is het onrealistisch dat het LLM hiervoor opnieuw een trainingsfase doorloopt. Dit proces kost namelijk veel tijd en miljoenen euro’s. Daarom wordt gebruikgemaakt van technieken als RAG. Om RAG toe te passen, worden vectordatabases, zoals LanceDB en Pinecone, of document-retrievalsystemen, zoals Elasticsearch en Haystack, ingezet.
Bij vectordatabases worden tekstdata door de ingebouwde ‘embedder’ vooraf omgezet in vectoren, vergelijkbaar met een LLM. Deze vectoren worden opgeslagen in een database die doorzoekbaar is op basis van vectorovereenkomsten. Dit maakt ze geschikt voor contextueel en semantisch zoeken, veel meer dan met traditionele SQL-databanken mogelijk is.
Document-retrievalsystemen slaan de data als tekst op, vaak in gestructureerde velden, waardoor full-text search mogelijk is op basis van trefwoorden en tekstuele overeenkomsten. Deze systemen zijn meer geschikt voor exacte tekstopzoekingen.
Interessante achtergrondinformatie over vectordatabases en hun relatie tot LLM’s vind je onder meer hier.
Tekstdata worden door de ingebouwde embedder in een vectordatabase ondergebracht.
3 RAG-zoekopdrachten
Hoe verloopt een RAG-zoekproces over het algemeen? Eerst upload je alle gewenste documenten naar het systeem. De tekstdata worden daarna, via een lokaal (Ragflow, AnythingLLM) of cloudgebaseerd (NotebookLM) embedding-model, in kleine stukken verdeeld en in een vectordatabase opgeslagen, lokaal of in de cloud.
Wanneer je nu een prompt invoert, wordt deze eveneens door het embedding-model gevectoriseerd. De vectordatabase zoekt vervolgens naar relevante tekstfragmenten op basis van overeenkomsten, waarna de relevantste fragmenten worden opgehaald. Deze fragmenten worden nu gecombineerd met je originele prompt en samen naar het LLM-model gestuurd, lokaal of via een API(-sleutel) naar een cloudmodel als ChatGPT. Het gegenereerde antwoord wordt daarna teruggestuurd naar je systeem.
Draait het RAG-systeem lokaal, dan worden dus alleen de relevante fragmenten en je prompt naar de cloud gestuurd, tenzij ook de chatbot lokaal draait. In dit geval blijft alles lokaal. Je volledige documenten en de bijbehorende vectoren blijven hoe dan ook lokaal, tenzij het hele RAG-systeem in de cloud draait.
Een typisch RAG-scenario: de prompt en (alleen) de relevante data gaan naar het LLM-model.
Veel gebruikers weten niet dat je een AI-bot ook via WhatsApp kunt bevragen. Zo benader je ChatGPT via het telefoonnummer +1 800 2428478. Commerciële bedrijven als het Nederlandse The AI-Book Company hebben inmiddels een verdienmodel ontwikkeld waarbij AI-boeken via WhatsApp worden aangeboden.
De volledige inhoud van een specifiek boek wordt hierbij geüpload naar een document-retrievalsysteem, zoals Elasticsearch of een vectordatabase als LanceDB, en via API’s gekoppeld aan WhatsApp en een AI-chatbot als ChatGPT. Als geregistreerde gebruiker (wat meestal zo’n 10 euro kost) kun je dan via WhatsApp concrete vragen stellen aan het boek, waarna de chatbot de antwoorden genereert. Je hoeft het boek dus niet noodzakelijk zelf eerst (volledig) te lezen.
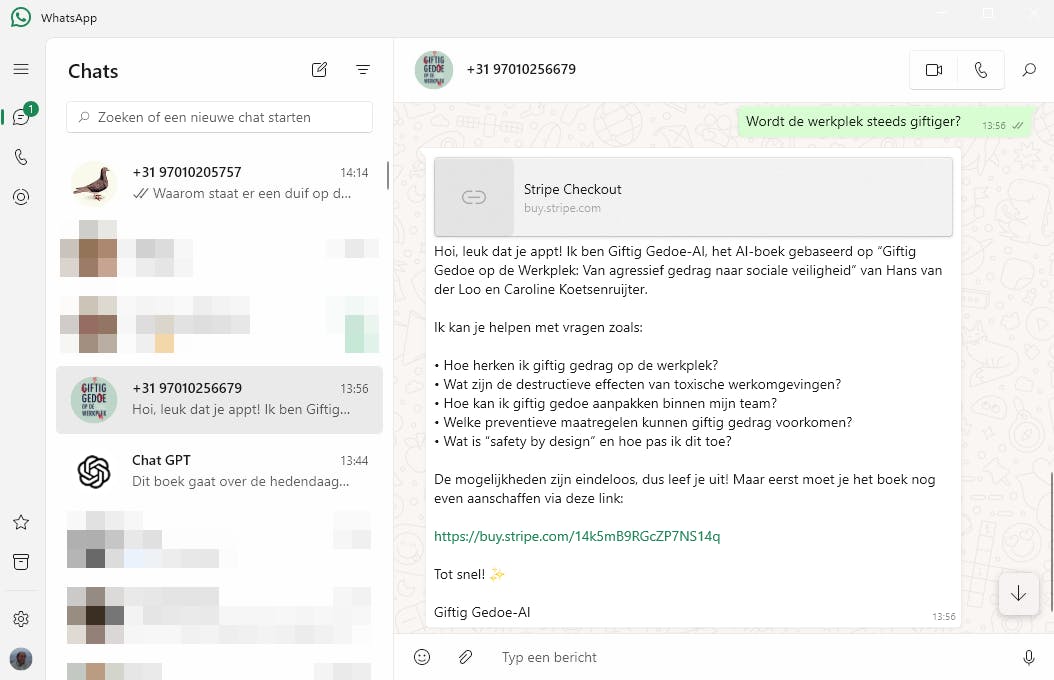 RAG-AI in de vorm van een WhatsApp-contactpersoon.
RAG-AI in de vorm van een WhatsApp-contactpersoon.
4 NotebookLM
Je weet nu ongeveer wat je met een RAG-systeem kunt en hoe dit onderliggend werkt. Hoog tijd nu om zo’n systeem aan de tand te voelen. We beginnen met een cloudgebaseerd RAG-systeem, Google NotebookLM, dat vooral geschikt is als privacy voor jou minder belangrijk is (al claimt Google je persoonsgegevens niet te gebruiken om NotebookLM te trainen).
Ga naar https://notebooklm.google en klik op de knop NotebookLM proberen. Meld je aan met een persoonlijk Google- of Google Workspace-account.
Je merkt dat er standaard al een notebook is aangemaakt: Introduction to NotebookLM. In het Bronnen-menu aan de linkerkant kun je zeven reeds toegevoegde documenten bekijken. Klik op een document voor een geautomatiseerde samenvatting en de belangrijkste aanklikbare onderwerpen. In het document NotebookLM Features lees je bijvoorbeeld welke documenttypes je kunt uploaden. Je kunt hierover open vragen stellen in het chatvenster, zoals: ‘Met welke types bronbestanden kan NotebookLM precies overweg?’ Het antwoord baseert zich grotendeels op tekstfragmenten uit dit document, zoals zichtbaar bij de genummerde bronverwijzingen.
De bot geeft bij de prompt netjes aan hoeveel bronnen hij kan raadplegen (zeven in dit geval). Stel je een vraag als ‘Is NotebookLM een Retrieval Augmented Generation-systeem (RAG)’, dan krijg je een gefundeerd antwoord met verwijzingen naar een of meer documenten, ook al wordt ‘RAG’ niet expliciet in deze documenten vermeld. NotebookLM vult namelijk antwoorden aan met eigen trainingsdata (van Gemini Pro in dit geval) wanneer dat zinvol is. Vragen die geen verband houden met je documenten blijven echter onbeantwoord.
Desnoods haalt NotebookLM aanvullende informatie uit de eigen trainingsdata op.
5 Bronnen toevoegen aan NotebookLM
We laten je zien hoe je een eigen notebook samenstelt. Een notebook kun je zien als een project dat uit meerdere documenten bestaat, vergelijkbaar met een map met bestanden. Klik op het pictogram linksboven om een overzicht van bestaande notebooks te zien. Kies hier + Nieuwe maken om documenten toe te voegen. Dit kunnen lokale bestanden zijn, zoals pdf’s, txt-bestanden en diverse audioformaten met spraak, maar ook documenten en presentaties uit Google Drive, links naar websites, publieke YouTube-video’s (met onderschriften) of tekst van het klembord. Per notebook kun je maximaal vijftig bronnen uploaden, elk tot 200 MB groot.
Audiobestanden worden automatisch intern getranscribeerd, zodat je er vragen over kunt stellen. Met de knop + Bron toevoegen voeg je meer bronnen toe aan een geselecteerd notebook. Met vinkjes bepaal je welke bronnen de dienst mag gebruiken bij vragen. Je kunt ook anderstalige documenten uploaden en in je voorkeurstaal, zoals Nederlands, vragen stellen en antwoorden ontvangen. De taalvoorkeur stel je in via de instellingen van je Google Account.
Ook anderstalige bronnen (rechts: een pdf in Adobe Reader) kun je meteen bestuderen en bevragen in je eigen taal.
6 Speciale notities in NotebookLM
Wil je antwoorden bewaren, klik dan op Notitie toevoegen. De notitie wordt opgeslagen onderaan het rechterdeelvenster Studio. Hier vind je ook nog allerlei andere knoppen:
- Veelgestelde vragen genereert een nieuwe notitie met korte vragen over de geselecteerde bronnen, inclusief antwoorden.
- Studiemateriaal deelt je bronmateriaal op in een glossarium, korte quizvragen met antwoorden en complexere essayvragen.
- Overzichtsdocument toont de belangrijkste feiten en inzichten uit je bronnen, inclusief een korte inhoud, kernpunten, relevante citaten en een conclusie.
- Tijdlijn geeft een chronologische lijst met belangrijke feiten, gebeurtenissen en eventueel betrokken personages.
- Audio-overzicht zet bronmateriaal om in een podcast-achtige Engelstalige conversatie, die als wav-bestand te downloaden is (en die je, indien gewenst, naar bijvoorbeeld mp3 kunt omzetten, zoals met het gratis Shutter Encoder). Het zou ons weinig verbazen als dit (in de Plus-versie?) binnenkort bijvoorbeeld ook in het Nederlands kan, met je eigen stem.
Je kunt notebooks delen met andere Google-gebruikers als Kijker of Bewerker, maar je kunt op elk moment ook weer de toegang intrekken. Wie NotebookLM in Pro gebruikt, kan de chatresponses verder bijsturen en meer notebooks, bronnen, vragen en overzichten maken. Dit abonnement biedt tot 500 notebooks, elk met maximaal 300 bronnen, en dagelijks 500 chatvragen en 20 audio-overzichten (meer informatie vind je hier).
Van een tijdlijn over studiemateriaal tot een heuse podcast met slechts enkele muisklikken.
7 Cloud versus lokaal
Tools als NotebookLM zijn bijzonder nuttig voor het bestuderen, analyseren en kritisch bevragen van zowel tekst- als audiobronnen. Een nadeel is dat je bronnen naar de cloud moet uploaden. Dat kan onhandig en tijdrovend zijn en vormt altijd een risico voor de privacy, ook al zegt Google deze data niet voor trainingsdoeleinden te gebruiken.
Met de juiste tools kun je dit proces ook deels of volledig lokaal uitvoeren, zodat er weinig tot geen data online komen. Een geschikte oplossing is de gratis tool AnythingLLM, een opensource-framework waarmee je LLM’s kunt beheren en gebruiken, zowel in de cloud (meestal via API’s) als lokaal. Je kunt het systeem bovendien uitbreiden met eigen data via RAG.
Het hele systeem van AnythingLLM kan ook in de cloud worden gehost. Zo’n gehoste oplossing kost ongeveer 50 dollar (ca. 48 euro) per maand voor vier gebruikers en honderd documenten) of 99 dollar (ca. 95 euro) per maand voor grotere teams of databibliotheken.
Wil je volledige controle, dan kun je zowel dataopslag, embedder, vectordatabase als het LLM-model lokaal draaien. Hosting kan op een eigen pc of server, bijvoorbeeld als uitvoerbare applicatie voor Windows, macOS of Linux. In Linux gebruik je bijvoorbeeld dit commando:
curl -fsSL https://cdn.useanything.com/latest/installer.sh | shEen andere optie is om een dockercontainer te gebruiken voor een meer geïsoleerde en schaalbare omgeving.
AnythingLLM laat zich makkelijk installeren voor diverse platformen.
8 AnythingLLM
We tonen hier hoe je met de desktopapplicatie (versie 1.7.2 in ons geval) voor Windows (x64) aan de slag kunt. Je installeert deze suite met diverse AI-tools via het uitvoerbare bestand in slechts een paar muisklikken, waarna de suite direct klaar is voor gebruik. De systeemeisen hangen af van wat je wilt doen, zoals het gebruik van een lokale embedder, vectordatabase en/of LLM. Officieel zijn 2 GB geheugen, een dualcore-cpu en 5 GB opslagruimte toereikend, maar dit zijn absolute minimumwaarden, geschikt als je vooral externe diensten (zoals in de cloud) gebruikt.
Bij de eerste keer opstarten van AnythingLLM klik je op Get started. Je selecteert vervolgens een geschikte LLM-provider voor het genereren van responses op basis van je prompts en meegestuurde tekstfragmenten. Standaard wordt hier AnythingLLM voorgesteld, die onderliggend Ollama gebruikt (zie het kader 'Ollama en RAGflow’). Kies uit de veertien voorgestelde LLM’s, met onder meer modellen van Meta, Microsoft, Google en Mistral. De meeste zijn tekstmodellen, maar een paar zijn multimodaal en ondersteunen in principe ook afbeeldingen. Bij elk model staat een GB-waarde die aangeeft hoeveel geheugen nodig is (bij voorkeur VRAM van de gpu). Laat je keuze mede hierdoor bepalen. Selecteer een model zodat de aanduiding Active verschijnt en druk op de rechterpijlknop.
Je kiest zelf de LLM die je binnen je werkruimte in AnythingLLM wilt gebruiken: lokaal of extern.
AnythingLLM profileert zich als een alles-in-één AI-applicatie, maar je kunt ook kiezen voor een handmatigere aanpak. Een combinatie van Ollama en een tool als RAGflow is een bruikbaar alternatief. Deze opzet vereist wel meer configuratie, maar RAGflow biedt meer opties voor finetuning.
Ollama (beschikbaar voor Windows, macOS en Linux) stelt je in staat om LLM’s lokaal te draaien of via API’s met cloudgebaseerde LLM’s te verbinden. Wil je zelf de locatie van de gedownloade LLM’s bepalen, maak dan in Windows een omgevingsvariabele aan: OLLAMAMODELS=<padnaar_downloadmap>. Op www.ollama.com/search kun je nu een LLM kiezen en het bijbehorende opdrachtregelcommando vinden, bijvoorbeeld ollama run llama3.2:1b. Je kunt je chatprompts meteen op de bijbehorende prompt invoeren.
RAGflow installeer je op Windows het eenvoudigst via Docker Desktop, nadat je WSL2 hebt geïnstalleerd (met het commando wsl --install). Download het zip-archief van RAGflow (druk op Code en Download ZIP). Raadpleeg de Readme voor meer details. Navigeer naar de uitgepakte map en voer hier dit commando uit:
docker compose -f docker/docker-compose.yml up
De container wordt nu toegevoegd in Docker Desktop. Zorg dat de container is gestart en open de webinterface van RAGflow via localhost:80 voor verdere configuratie, na je aanmelding. Bij Model Providers kun je nu Ollama selecteren en uit een van de gedownloade LLM’s kiezen.
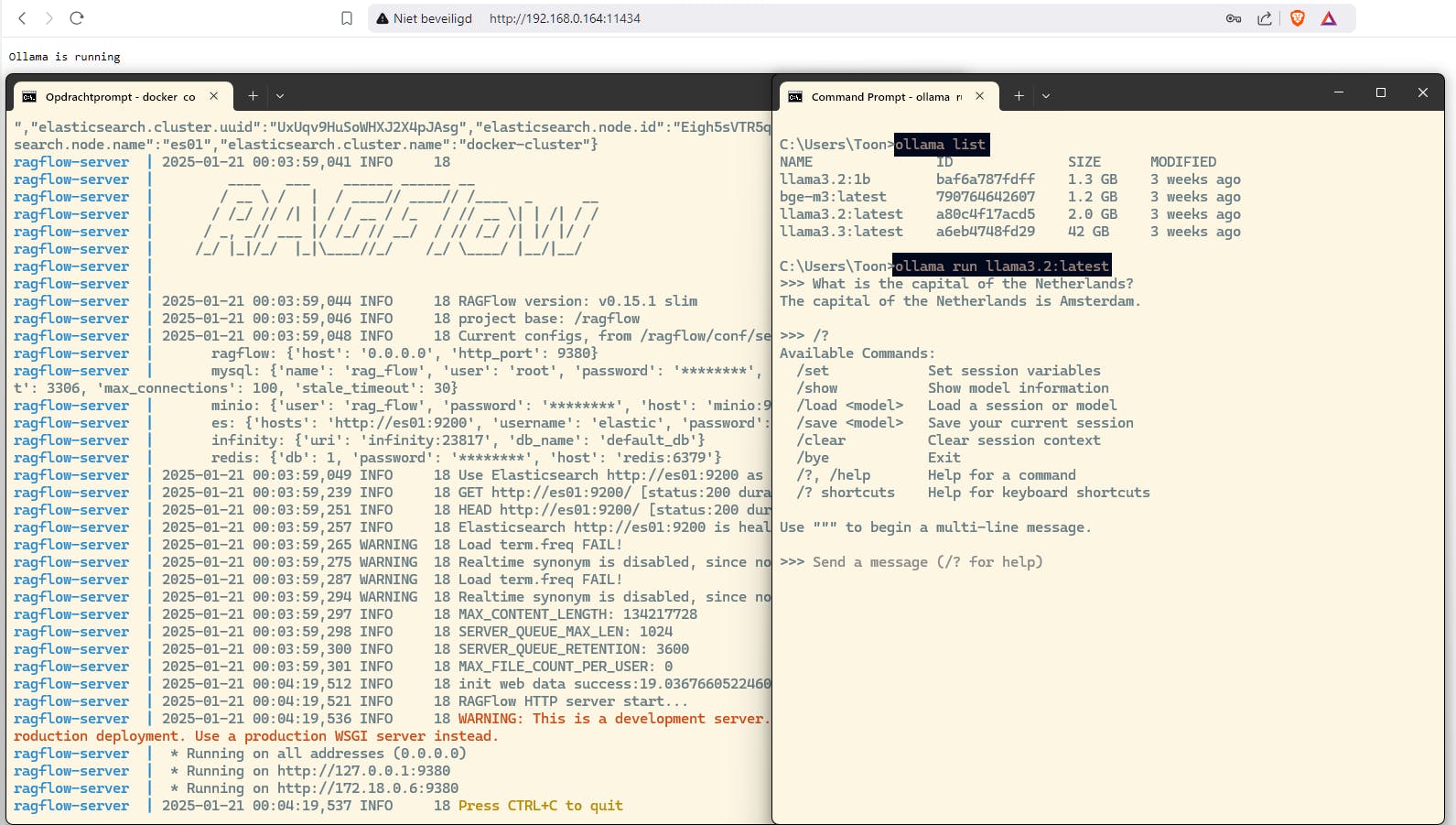 RAGflow met Ollama: een sterk duo, maar wel wat set-up- en configuratiewerk.
RAGflow met Ollama: een sterk duo, maar wel wat set-up- en configuratiewerk.
9 Werkruimtes
Je komt op een overzichtspagina terecht waar je naast de gekozen LLM (in dit voorbeeld AnythingLLM x Ollama) ook de standaard geselecteerde embedder (Anything LLM Embedder) en de vectordatabase (LanceDB) ziet. AnythingLLM kiest bewust voor lokaal werkende oplossingen om je privacy te beschermen. Je kunt deze instellingen later wijzigen, maar bevestig nu met de rechterpijlknop. Klik eventueel op Skip Survey en vul de naam in van je eerste werkruimte. Een werkruimte functioneert als container voor documenten en gesprekken rond een specifiek thema of project, zodat je gestructureerd kunt werken.
Nadat je op de rechterpijlknop hebt gedrukt, verschijnt het hoofdvenster van AnythingLLM: links zie je de werkruimtes en rechts een welkomstvenster. Via de knop + Nieuwe Werkruimte kun je extra werkruimtes aanmaken. Een naam geven is voldoende, omdat nieuwe werkruimtes standaard de net ingestelde algemene instellingen overnemen.
Klik op het tandwielpictogram bij een werkruimte. Op het tabblad Algemene instellingen kun je de naam wijzigen of de werkruimte verwijderen. Weet wel dat alles wat je embed in de vectordatabase van toegevoegde bronbestanden verdwijnt bij verwijdering. De bronbestanden zelf blijven behouden.
Je kunt werkruimtes maken, benoemen en ook weer verwijderen.
10 Bronbestanden
Je voegt bronbestanden als volgt aan je werkruimte toe. Klik vanuit het hoofdvenster op de uploadpijl naast de werkruimte. Er opent een dialoogvenster met twee knoppen: Documents en Data Connectors. Via Documents kun je diverse bestandstypes uploaden, zoals txt-, pdf-, csv- en xls(x)-bestanden, of ze direct verslepen naar het venster. Deze bestanden worden door de ingebouwde document-processor geanalyseerd (waarbij ze worden opgesplitst in brokken (chunks) van een instelbaar aantal tokens) en vervolgens in het deelvenster My Documents geplaatst. Documenten die je eerder in andere werkruimtes hebt toegevoegd, zijn hier ook beschikbaar (met de indicatie Cached). Je kunt ook naar webpagina’s of online documenten verwijzen door de url in te voeren en op Fetch website te klikken. Toegevoegde documenten worden standaard geplaatst in de map custom-documents, maar je kunt ze ook organiseren in nieuwe mappen via + New Folder.
Selecteer documenten die je wilt gebruiken in de werkruimte en klik op Move to Workspace. Controleer ook de knop Data Connectors. Hiermee kun je (online) documenten ophalen via diensten als GitHub Repo, GitLab Repo en Confluence, of zelfs YouTube-transcripts en webpagina’s via Bulk Link Scraper. Bij deze scraper vul je een url in, plus de gewenste linkdiepte en het maximaal aantal te lezen pagina’s. Deze gegevens worden dan eveneens aan je documenten toegevoegd.
Bevestig met Save and embed om de documenten in de vectordatabase te embedden. Dit proces kan, afhankelijk van de hoeveelheid data, wel even duren.
Voeg alle gewenste bronbestanden (zoals documenten of webpagina’s) toe aan het systeem.
11 Chatomgeving
In het hoofdvenster open je de gewenste werkruimte. Standaard is er al één thread actief (Default): een conversatie tussen jou en de LLM. Je kunt extra threads aanmaken via + New Thread. Voer je prompts in en de LLM geeft (hopelijk relevante) antwoorden op basis van de doorgestuurde tekstfragmenten. Klik op Show Citations om te zien welke bronnen zijn gebruikt. Door op een bron te klikken, zie je de specifieke tekstfragmenten. Je kunt prompts ook inspreken (microfoon-pictogram) en de antwoorden laten voorlezen (luidspreker-pictogram).
Daarnaast zie je een paperclip-pictogram voor het ad hoc uploaden van extra documenten en een pictogram voor slash-commando’s en agents. Het standaard beschikbare slash-commando is /reset, waarmee je je chatgeschiedenis wist en een nieuwe sessie start. Voeg via Add a New Preset eigen commando’s toe, zoals /vertaal met een prompt als ‘Vertaal het zojuist gegeven antwoord naar het Engels’ en Engelse vertaling als beschrijving. Deze commando’s komen automatisch ook beschikbaar in je andere threads en werkruimtes.
Overigens kun je je chatgeschiedenis (van alle werkruimtes) ook bekijken, exporteren en verwijderen via het moersleutel-pictogram, in de categorie Beheerder / Werkruimte Chats.
Slash-commando’s: handig voor vaak gebruikte prompts.
12 Agents
Agents functioneren als autonome modules die AI-modellen gebruiken om specifieke taken zelfstandig uit te voeren, zoals informatie verwerken of acties uitvoeren op basis van ingestelde parameters. Klik op het moersleutel-pictogram linksonder (Open settings) en navigeer naar Agent Vaardigheden. Hier vind je standaard zeven geïntegreerde agents, waarvan je er vier kunt in- of uitschakelen, zoals Generate charts en Web Search.
We nemen deze laatste als voorbeeld. Activeer deze, selecteer een SERP (Search Engine Results Provider), bijvoorbeeld DuckDuckGo (bij sommige moet je wel nog een API-sleutel invullen). Bevestig met Save. Laat nu in de chatomgeving je prompts voorafgaan door @agent om automatisch geactiveerde en relevante agents op te roepen. Zo kan de agent actuele informatie van internet ophalen, waarbij standaard tot tien zoekresultaten worden verwerkt.
Verwant aan agents zijn de ‘agent skills’. Open de rubriek Community Hub en ga naar Explore Trending. Klik bij een skill op Import en bevestig met Import Agent Skill. Ga daarna terug naar Agent Vaardigheden, waar de skill is toegevoegd. Schakel de skill in om deze beschikbaar te maken.
Met en zonder zoekopdrachten op het web: een merkbaar verschil.
13 Instellingen
Via Open settings kun je op algemeen niveau diverse onderdelen aanpassen. In de categorie AI Providers wijzig je bijvoorbeeld de LLM, Vector Database en Inbedder, zoals een cloudgebaseerde dienst als OpenAI, Pinecone of Gemini. Voor veel opties is een API-sleutel vereist, die vaak niet gratis is. Je stelt hier ook spraak-naar-tekst- (standaard: Local Whisper) en tekst-naar-spraak-providers in. Voor tekst-naar-spraak is standaard de lokale provider PiperTTS ingesteld, maar je kunt bijvoorbeeld ook een bekende dienst als ElevenLabs kiezen (met API).
Bij Aanpassing stel je het thema, de taal en de automatische berichten voor gebruikers in. Deze instellingen gelden standaard voor alle werkruimtes, maar kunnen op werkruimteniveau worden overschreven. Klik op het tandwielpictogram naast een werkruimte om deze opties aan te passen.
In het tabblad Chat Instellingen kies je een specifieke LLM Provider of stel je de Chatmodus in. Standaard staat dit op Chat, maar met de optie Query gebruikt het systeem uitsluitend je eigen documentcontext voor responses, zonder de getrainde dataset van de LLM te raadplegen. Hier bepaal je ook hoeveel eerdere chats worden meegenomen (standaard 20) en met welke achterliggende prompt de werkruimte rekening moet houden.
Op het tabblad Agent Configuratie kun je agenten en skills selecteren die specifiek voor deze werkruimte gelden. Bevestig alle aanpassingen telkens met de voorziene knoppen.
Je kunt ook instellingen vastleggen die specifiek zijn voor de geselecteerde werkruimte.





















