Paperless-ngx: zoek en gij zult vinden


Wil je orde scheppen in je verzameling documenten, zoals je administratie, polissen of handleidingen? Of heb je nog een stapel dossiers om door de scanner te halen voor een digitaal archief? Paperless-ngx is een van de mooiste toepassingen hiervoor, met uitgebreide zoek- en indexeringsmogelijkheden. Het is geschikt voor pdf-bestanden, biedt tekstherkenning met OCR en kan met nog veel meer bestandsformaten overweg.
In dit artikel laten we zien hoe je met Paperless-ngx je documenten kunt digitaliseren, doorzoeken en beheren:
- Installeer Paperless-ngx via Docker Compose op je eigen systeem of NAS
- Pas de ingestelde mappen en netwerkpaden aan in het docker-compose.yml-bestand
- Start de containers, maak een superuser aan en log in op je dashboard
- Upload documenten via drag-and-drop of plaats ze in de consume-map
- Wijs documenten een type, correspondent en labels toe voor slimme filtering
- Bewerk documenten handmatig of in bulk om metadata aan te vullen
- Sla veelgebruikte filters op voor snel hergebruik
Lees ook: Zoek de verschillen! Zo ontdek je snel of de inhoud van jouw mappen écht hetzelfde is
Hoewel je je administratie, polissen of handleidingen netjes in mapjes kunt bewaren, zul je soms het overzicht missen, en anders wel een goede zoekfunctie. Een documentbeheersysteem als Paperless-ngx kan een heel goede hulp zijn. Het maakt het indexeren en doorzoeken van documenten veel eenvoudiger. Er is ondersteuning voor uiteenlopende bestandsformaten, waaronder natuurlijk pdf-bestanden, maar ook Office-documenten en afbeeldingen. Zo kun je het nóg flexibeler inzetten. Je kunt documenten organiseren en indexeren op documenttype of met de hulp van labels. Dankzij OCR (Optical Character Recognition) kan tekst in documenten worden herkend en doorzoekbaar gemaakt.
De software is opensource en kent een vrij lange geschiedenis. Voor de oorsprong van Paperless-ngx moeten we terug naar 2015. De Britse softwareontwikkelaar David Quinn zette toen het Python-project Paperless op voor persoonlijk gebruik, maar het ging aan zijn eigen populariteit ten onder. Het leverde meer dan 500 forks op (!), waarvan Paperless-ng de voornaamste versie was. Die bracht veel veranderingen en een flink vernieuwde gebruikersinterface. Ook dit project kreeg een opvolger, genaamd Paperless-ngx (Next Generation eXtended), dat nu door de gemeenschap wordt onderhouden.
In dit artikel laten we zien hoe je Paperless-ngx kunt installeren en gebruiken. Je kunt het systeem zelf hosten, bijvoorbeeld via Docker Compose. Dat maakt het privacy-vriendelijk. Voor het beheer is alleen een browser nodig.
1 Wat heb je nodig?
Paperless-ngx, of kortweg Paperless, is een relatief licht programma. Het kan genoeg kan hebben aan een Raspberry Pi, maar het heeft wel baat bij een krachtiger systeem. Dat zal in ieder geval de verwerkingstijd aanzienlijk verkorten.
Zorg in elk geval voor betrouwbare opslag en een back-upstrategie. Qua database kun je kiezen uit SQLite, MariaDB (MySQL) en PostgreSQL. Voor licht gebruik op Raspberry Pi of NAS heeft SQLite de voorkeur. Maar voor intensief gebruik of een krachtiger systeem is PostgreSQL geschikter en dat is ook de aanbevolen keuze voor nieuwe installaties. Voor aanvullende informatie kun je terecht op GitHub of raadpleeg je de documentatie.
Raadpleeg de website van Paperless voor meer informatie.
2 Installatie
De aanbevolen installatiemethode is via Docker Compose. De installatie van Docker en Docker Compose is vaker aan bod gekomen. Online vind je ook gidsen, zoals voor Ubuntu 24.04.
Voor Paperless zijn twee bestanden nodig: docker-compose.yml en docker-compose.env. Je kunt via deze website voorbeelden downloaden. Het .yml-bestand beschrijft de containers en het .env-bestand bevat enkele omgevingsvariabelen.
Paperless-ngx kan samenwerken met Apache Tika, als je een van de Docker Compose-voorbeelden met -tika in de naam gebruikt. Tika is een opensource-bibliotheek voor de analyse van documenten en tekstextractie uit die documenten. Als je deze variant kiest, kun je veel meer bestandsformaten lezen en converteren naar pdf (via een tool genaamd Gotenberg), zodat je ze vervolgens kunt gebruiken binnen het documentbeheersysteem. Dit gaat onder meer om de bekende Office-documenten (Word, Excel en PowerPoint), e-mailberichten en zip-bestanden.
Tika is overigens niet nodig als je alleen tekst uit pdf-bestanden wilt halen. Daarvoor wordt standaard Tesseract OCR gebruikt. Via deze GitHub-pagina vind je varianten voor de verschillende databases, en met of zonder Apache Tika.
Wij kiezen docker-compose.postgres-tika.yml als basis en het standaard bestand docker-compose.env. In beide bestanden gaan we in de volgende paragrafen nog aanpassingen maken.
Gebruik een van de bestanden voor Docker Compose als voorbeeld.
3 Aanpassen compose-bestand
In je docker-compose.yml zie je een opsomming van alle containers. Dat zijn bij onze setup broker, db, webserver, gotenberg en tika. Hierin zul je wellicht enkele aanpassingen willen maken. We beginnen onder volumes: waar je verwijzingen naar de belangrijkste mappen ziet:
Standaard wordt de lokale map ./consume gebruikt, die wordt aangemaakt als deze nog niet bestaat. Het programma wacht geduldig op nieuwe documenten die in deze map worden geplaatst, bijvoorbeeld handmatig of via een netwerkscanner. Je kunt de map eventueel aanpassen, zodat in plaats van de lokale map bijvoorbeeld een mount naar een NAS wordt gebruikt, bijvoorbeeld:
Paperless verwerkt bestanden in de genoemde map automatisch en verplaatst ze naar media (hier een Docker-volume) waar je handmatig een back-up voor kunt maken (zie kader ‘Back-ups maken van je documenten’).
Een laatste aandachtspunt is de standaardpoort (8000) voor de webserver onder ports:. Bij een potentieel conflict kun je dit aanpassen zodat op de host bijvoorbeeld 8010 wordt gebruikt:
We maken enkele aanpassingen in het bestand voor Docker Compose.
Het is raadzaam een back-up van je documenten te bewaren. Paperless biedt hiervoor meerdere opties. Ten eerste kun je documenten exporteren. De export omvat alle relevante gegevens, waaronder de documenten zelf, thumbnails, metagegevens en inhoud van de database. Hiervoor geef je in de map met Paperless de volgende opdracht: docker compose exec -T webserver document_exporter ../export
Bij Docker kun je ook kiezen om een back-up van de volumes te maken. Deze vind je op de meeste systemen onder /var/lib/docker/volumes. De belangrijkste voor de hier besproken setup zijn paperless_media met alle documenten en paperless_pgdata met de PostgreSQL-database.
4 Aanpassen variabelen
Het bestand docker-compose.env bevat optionele omgevingsvariabelen. We maken hier enkele aanpassingen in. Je kunt het gedownloade bestand als uitgangspunt nemen. Voor de regels die je gaat gebruiken moet je uiteraard het commentaarteken (#) weghalen. Eerst stellen we de correcte tijdzone in:
Verder geven we aan wat de primaire taal is voor het verwerken van documenten met OCR. Als alle documenten in het Nederlands zijn, gebruik je:
Heb je documenten in meerdere talen, bijvoorbeeld Nederlands en Engels? Dan kun je die zoals hieronder combineren. Bij verwerking met OCR wordt nu gezocht naar een match met Nederlands of Engels. Dit vraagt wel meer verwerkingskracht.
Standaard zijn alle taalbestanden voor Engels, Duits, Italiaans, Spaans en Frans geïnstalleerd. De Nederlandse taal moet nog wel expliciet worden geïnstalleerd. Daarvoor gebruik je de volgende omgevingsvariabele:
Merk op dat je Paperless als rootgebruiker moet uitvoeren om die laatste regel te kunnen gebruiken.
We passen via de omgevingsvariabelen wat opties aan voor OCR.
5 Container starten en updaten
Voordat je de container start, is het handig om eerst alle gebruikte images voor de containers op te halen met:
Je hebt een zogenoemde superuser nodig om in te kunnen loggen. Die kun je maken met:
Er wordt om een gebruikersnaam, e-mailadres en wachtwoord gevraagd. Vul eventueel tijdelijk een eenvoudig wachtwoord in, wat je later kunt aanpassen. Start daarna de container met:
Updates voor Paperless kun je eenvoudig installeren door eerst de nieuwe images op te halen met:
Vernieuw daarna de container met:
Wil je iets wijzigen? Stop dan eerst de container met:
Start daarna de container met de nieuwe configuratie.
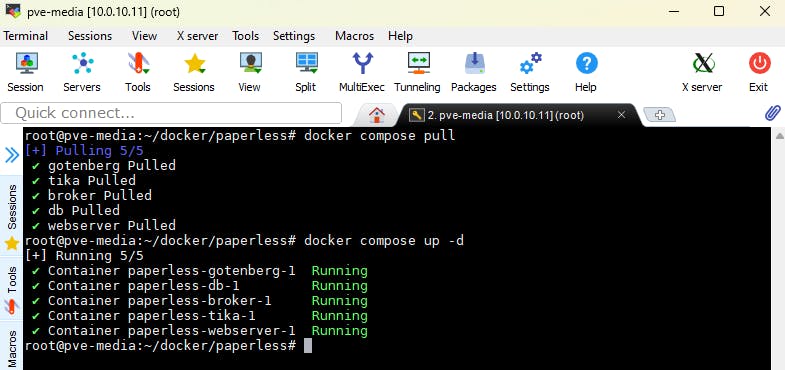
Via enkele opdrachten kun je images vernieuwen of de containers starten.
6 Dashboard
Je kunt nu via http://ipadres:8000 (of het door jou aangepaste poortnummer) inloggen bij Paperless. Gebruik het account dat je hiervoor hebt aangemaakt. Je komt dan in het dashboard. Op je dashboard zie je een knop om de rondleiding te starten. Dit geeft een indruk van de belangrijkste opties binnen Paperless.
Als je rechtsboven op je naam klikt en naar Mijn profiel gaat, kun je eventueel je wachtwoord veranderen naar een sterker wachtwoord of je gegevens aanvullen. Ook kun je hier optioneel tweestapsverificatie aanzetten, waarvoor je een app als Google Authenticator of Aegis kunt gebruiken. Deze extra beveiliging is vooral aanbevolen als je gevoelige informatie gaat uploaden, zoals je administratie of garantiebewijzen.
Je komt na het inloggen in je dashboard, waar je een rondleiding kunt starten.
Paperless-ngx heeft zelf geen echte AI-opties. Dat is jammer, want omdat een groot taalmodel vaak uitblinkt in het verwerken van tekst, zou het goed kunnen helpen bij bijvoorbeeld het indexeren van documenten of het voeren van conversaties over de inhoud. Met Paperless-AI is er een losstaand initiatief dat je voor dit doel kunt gebruiken in combinatie met Paperless-ngx. Zo kun je bijvoorbeeld automatisch labels toevoegen, het documenttype bepalen en vragen over documenten stellen. Je kunt OpenAI of Ollama gebruiken als backend voor AI.
7 Document toevoegen
We voegen om te beginnen een document toe in de vorm van een pdf-bestand. Dat kan op meerdere manieren. Om te beginnen zie je op je dashboard een vak voor uploads waar je via Selecteren een of meerdere bestanden kunt kiezen. Maar je kunt de bestanden ook naar dat vak slepen of gewoon naar een willekeurige pagina in Paperless in de browser. Een andere manier is om ze in de consume-map te plaatsen. Als je een scanner gebruikt, kun je ervoor zorgen dat de scanner ze zelf in die map zet.
Na het uploaden wordt het bestand verwerkt. Op je dashboard zie je een melding van verwerkte documenten. Ook worden de gegevens bij Statistieken bijgewerkt. Als voorbeeld hebben we enkele handleidingen toegevoegd, inclusief enkele gescande documenten.
Via de beheerdersomgeving kun je documenten uploaden.
8 Gegevens voor documenten
Normaal ben je wellicht gewend om bestanden in mapjes onder te verdelen. In Paperless werkt dat anders, maar ben je wel veel flexibeler, omdat je allerlei details kunt invullen waar je vervolgens op kunt filteren. De belangrijkste details zijn documenttype, correspondent en labels.
Via het documenttype geef je aan wat voor soort document het is, zoals een contract, factuur, handleiding of polis. Een correspondent is in feite de afzender of partij die het document heeft verstuurd, zoals KPN bij een telefooncontract. Met labels kun je vrijelijk verdere details verstrekken om op te filteren. Tijdens het bewerken van een document kun je onder andere nieuwe labels toevoegen, maar je kunt ze ook beheren via de opties in het menu onder Beheren.
Je kunt allerlei informatie toevoegen in de vorm van labels.
9 Documenten bewerken
Als je naar Documenten gaat, zie je de toegevoegde documenten die je individueel of in bulk kunt bewerken. Hoewel tekst bijvoorbeeld al doorzoekbaar is, is het zinvol om gegevens van documenten aan te vullen. Onder elk document zie je opties om deze te openen, een preview te bekijken of te downloaden.
Open eerst een document. Je ziet rechts een voorbeeld en links kun je gegevens aanpassen. Op het tabblad Details kun je correspondenten, documenttypes en labels kiezen. Gebruik het plusteken voor nieuwe details, zoals een nieuw label. Verder kun je een serienummer voor je archief opgeven, wat je kan helpen om het makkelijker terug te vinden. Merk op dat je in de navigatiekolom steeds een lijst met documenten ziet die momenteel zijn geopend voor bewerking.
Je kunt per document gegevens toevoegen.
10 Zoeken en filteren
Heb je een aantal documenten bewerkt, dan kun je wat beter de zoek- en filteropties gaan verkennen onder Documenten. Bovenaan kun je uit drie weergavestijlen kiezen: als lijst, of als kleine of grote kaart. Via de zoekbalk kun je de titel of inhoud van de tekst doorzoeken. En via filters kun je bijvoorbeeld bepaalde documenttypen of labels zichtbaar maken, of een datumbereik kiezen.
Heb je bijvoorbeeld voor handleidingen het documenttype handleiding gebruikt en het label camera voor camerahandleidingen, dan kun je deze via dit documenttype en label eenvoudig boven water halen. Je kunt ook labels uitsluiten, bijvoorbeeld: alle documenten met het label camera, maar niet met het label drone. Wil je terug naar een weergave met alle documenten, dan kies je Filters terug zetten.
Via filters kun je in detail de gewenste documenten naar voren halen.
11 Weergave opslaan
Een combinatie van filters kun je handig als een zogenoemde weergave opslaan. Stel dat je de camerahandleidingen vaak nodig hebt. Dan maak je de selectie zoals in de vorige stap. Daarna kies je rechtsboven voor Weergaven en vervolgens Opslaan als. Vul nu een naam in voor de weergave en vink naar voorkeur de opties Toon in de zijbalk en Toon op het dashboard aan, om hier nog sneller toegang toe te krijgen.
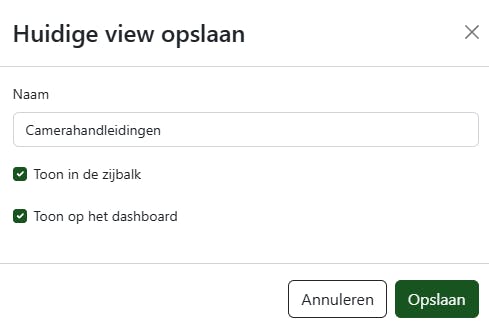
Een weergave kun je opslaan als je die vaker nodig hebt.
12 Foutmeldingen oplossen
We liepen bij één document tegen een foutmelding aan bij het renderen door Ghostscript. Dit komt omdat het gerelateerde OCRmyPDF strikter is geworden in hoe het omgaat met renderfouten bij conversies. Als Ghostscript een fout tegenkomt, zal OCRmyPDF de verwerking stoppen. Wil je dat het doorgaat met een mogelijk onbetrouwbaar resultaat? Dan kun je een aanpassing in het bestand docker-compose.yml maken. Voeg bij de container genaamd webserver, onder het kopje environment, de volgende regel toe:
Dit heeft in onze situatie het probleem verholpen. Merk op dat Paperless het originele document standaard ook behoudt. Importproblemen kun je overigens terugzien onder Bestandstaken en foutmeldingen zie je onder Logbestanden. Ook kun je de logs via Docker bekijken. Met docker ps zie je een lijst met actieve containers. Geef daarna de opdracht docker logs gevolgd door de ID of naam van de container, bijvoorbeeld:
Heb je een ander probleem? Paperless heeft op de website een sectie met mogelijke problemen en oplossingen.
Via de opdrachtprompt kun je uitgebreide logbestanden bekijken.
Er zijn nog enkele geavanceerde mogelijkheden, die in sommige situaties nuttig zijn. Zo kun je een opslagpad kiezen. Dat is in feite de locatie waar het document fysiek wordt opgeslagen in het bestandssysteem. Ook kun je rechten instellen, waarmee je kiest wie de eigenaar is en welke gebruikers of welke groep gebruikers het document mogen bekijken en/of bewerken.
Onder Aangepaste velden kun je zelf velden toevoegen met een naam en gegevenstype. Hier kun je desgewenst ook op filteren. Voor je handleidingen zou je bijvoorbeeld een aangepast veld van het type boolean kunnen maken, waarmee je aangeeft of je het bewuste apparaat nog gebruikt. Daarna kun je filteren op alleen de gebruikte apparaten.
Onder Workflows kun je aangepaste regels instellen die helpen bij het organiseren en verwerken van documenten. Verder kun je een e-mailaccount toevoegen, om documenten die je per e-mail ontvangt automatisch te verwerken, met specifieke regels.


