Tado Slimme Thermostaat review
Afgelopen herfst, winter en lente testten we de slimme kamer- en radiatorthermostaten van de Duitse fabrikant Tado. Het systeem werkt met vrijwel alle verwarmingssystemen van alle merken, maakt niet uit hoe oud. Bespaar je daar nu echt geld mee en zo ja hoeveel? Lees het in deze Tado Slimme Thermostaat review.
Het Duitse Tado is sinds 2014 actief als Europees alternatief voor de slimme thermostaten van Amerikaanse bedrijven zoals Honeywell (Evohome Smart Thermostat) en Google/Alphabet (Nest Learning Thermostat). Het bedrijf wordt sinds juni 2017 geleid door Eindhovenaar Toon Bouten (ex-Compaq Computers, ex-Philips Consumer Electronics). Privacyminnende gebruikers geven mogelijk de voorkeur aan een Europees (Duits) product, want slimme thermostaten werken het best wanneer ze steeds precies je locatie volgen. Dan kan de verwarming automatisch lager gezet worden wanneer bewoners niet thuis zijn. Dat zorgt voor de grootste besparingen.
Het is nog maar de vraag wat Amerikaanse bedrijven met al die privacygevoelige locatiegegevens doen. Tado valt onder de Duitse en Europese privacy- en datawetgeving en heeft een strenge en transparante privacypolitiek die je op hun website terugvindt.
We testten de Slimme Thermostaat – Starterskit (v3) die een traditionele huiskamerthermostaat vervangt. Ook testten we de starterskit met twee slimme radiatorknoppen. Die vervangen de traditionele radiatorthermostaten. De radiatorthermostaat gebruik je apart per verwarmingstoestel of in combinatie met de slimme huiskamerthermostaat.
Tado stuurt de verwarming aan op basis van je locatie. Je controleert alles met je smartphone, tablet (via de apps voor Android en iOS) en/of pc (via de webapp). De slimme thermostaat kan verder worden bediend met behulp van Apple HomeKit, Amazon Alexa, Google Assistant en/of IFTTT.
Elk nieuw Tado-apparaat wordt standaard toegewezen aan een zone. Een nieuwe zone creëren of toewijzen gebeurt tijdens de installatie van het apparaat, of achteraf door in het afrolmenu de optie Apparaat toewijzen aan een andere zone te kiezen. Elke zone programmeer en regel je apart. Minpuntje is dat je je zelf samengestelde schema’s niet van zone naar zone kunt kopiëren, zoals dat bijvoorbeeld wel mogelijk is bij de slimme thermostaten van Honeywell.


©PXimport
Geofencing
In elke zone creëer je een eenvoudig of een slim verwarmingsschema en dit voor elke dag apart of voor gegroepeerde dagen (zoals weekend en week). In elk van die schema’s configureer je verschillende tijdsblokken met elk hun eigen temperatuurinstelling. Dat verschilt niet zo erg veel van wat mogelijk is met elke digitale thermostaat, slim of niet.
Het slimme van Tado zit hem in de ‘geofencing’-functie die de verwarming automatisch regelt afhankelijk van of er iemand thuis is of niet. Om dit goed te laten werken dien je de Tado-app te installeren op de smartphone van elke bewoner.
Veel geofencing-apps (bijvoorbeeld Nest) eisen dat je permanent de hoge-precisiemodus voor de gps-functie activeert. Dat vormt een zware belasting voor de accu van je mobiel. Tado is slimmer en werkt, zo blijkt uit onze maandenlange test, perfect als je de gps op spaarstand laat staan (of zelfs regelmatig helemaal uitschakelt). Het gebruikt immers ook andere, energiezuinigere, maar minder precieze methodes om je locatie te weten te komen, bijvoorbeeld wifi-en mobiele (gsm)-verbindingen.
Het is wel belangrijk dat de app in de achtergrond blijft werken (dus door bijvoorbeeld Android of een app niet automatisch wordt uitgeschakeld om stroom te besparen). Tado heeft een faq die de optimale instellingen voor je smartphone opsomt. Voor een goede werking van het systeem volg je dus het best de instructies in die faq.
Functies
We hebben de app zowel op Android als iOS gebruikt en merkten nauwelijks een negatieve invloed op de accuprestaties, terwijl Tado toch vrij goed detecteerde wanneer we de testlocatie verlieten. Tado zet de verwarming automatisch lager bij afwezigheid, maar je kunt een ondergrens configureren in de (web)app. De slimme thermostaat zet de verwarming opnieuw aan wanneer je naar huis komt. Via de app kun je dit uitschakelen of in drie standen zetten: eco (begint pas te warmen wanneer je daadwerkelijk thuis bent); balans (verwarmt wanneer je het huis nadert); of comfort (de minst zuinige stand).
Nog een slimmigheidje: Tado houdt rekening met de weervoorspelling en zal de verwarming automatisch harder laten werken bij een voorspelde koude dag, of omgekeerd minder hard wanneer warm weer is voorspeld. Ook is er een goed functionerende ‘open raam’-detectie die de verwarming automatisch tijdelijk uitschakelt als de thermostaat een open deur of raam detecteert. De schakeltijd bepaal je zelf. Deze detectie werkt zowel op de thermostaat als op de radiatorknop.

©PXimport
Tado Slimme Thermostaat installeren
In de Starter Kit vind je de Smart Thermostat v3, de Internet Bridge, kabels en het nodige (Engelstalige) documentatiemateriaal. De installatiegids voor professionelen bevindt zich in een dichtgeplakte envelop. Doe je de zelfinstallatie dan gebruik je de ‘Welcome Guide’, die je eerst vraagt om een account te creëren (of in te loggen op een bestaand account).
De tado-cloud waaraan de thermostaat gekoppeld wordt, werkt wel (ook) in het Nederlands. De piepkleine internetbridge koppel je aan je router. Het apparaatje betrekt zijn stroom van een usb-kabel die je ofwel in een vrije usb-poort van de router ofwel in een aparte usb-voeding prikt. Enkele seconden na het aansluiten detecteert de installatiewizard de aanwezigheid van de bridge. Vervolgens registreer je de Smart Thermostat door het serienummer en de authenticatiecode in te vullen. Op dezelfde manier koppel je de radiatorknoppen en/of eventuele extra kamerthermostaten.
De installatiewizard bevat vele combinaties van thermostaten en verwarmingsketels, maar als jouw specifieke apparaat niet gevonden wordt, kun je de gegevens doorsturen naar de supportafdeling. Iemand bij Tado controleert dan wat je precies moet doen voor een succesvolle installatie. Het duurt even voordat je via e-mail verdere instructies ontvangt, maar in ons geval ontvingen we die binnen het uur en bovendien in het Nederlands. Overigens kun je ook foto’s uploaden zodat de ingenieurs de bestaande installatie gemakkelijker kunnen herkennen en je zo goed mogelijk verder kunnen helpen.
De zelfinstallatie lukte bij ons redelijk goed, al moesten we enkele keren de helpdesk contacteren omdat sommige stappen ons niet helemaal duidelijk waren. Uiteraard kun je Tado ook gewoon door een professional laten installeren, maar dat is uiteraard niet gratis.
Elke bridge kan maximaal 25 radiatorthermostaten controleren, of tien radiatorthermostaten in combinatie met één door een Tado-kamerthermostaat aangestuurde boiler. Elke verwarmingszone kan acht apparaten bevatten, bijvoorbeeld één thermostaat en zeven radiatorthermostaten.
De witte kamerthermostaat heeft een ledmatrixdisplay dat alleen actief is als je de thermostaat lokaal bedient. Zo gaan de drie AAA-batterijen één tot twee jaar mee. De thermostaat werkt volgens Tado met 95% van alle verwarmingssysteem, zowel centrale als vloerverwarming en kan zowel bedraad als draadloos worden gebruikt. Bij draadloos gebruik heb je wel een extra ketelmodule oftewel Extensiekit nodig.
Het is mogelijk om de thermostaat lokaal te bedienen via het display, maar de (web)app geeft je veel meer mogelijkheden en is dus de aangewezen bedieningsmethode.
Wil je meerdere verwarmingscircuits aansturen dat kan dit met een aanvullende kamerthermostaat die via dezelfde bridge werkt. Onze testlocatie heeft twee verwarmingscircuits en wij installeerden daarom twee kamerthermostaten.
Radiatorknoppen
De witte radiatorknoppen hebben een draaiknop om de temperatuur te regelen en tevens een eigen ledmatrixdisplay. Via de app is het overigens mogelijk om de lokale bediening per knop uit te schakelen. Je schroeft ze op een tussenzetstuk of ‘mount’ die aangepast is aan verschillende modellen radiatoren. In de verpakking vind je tussenzetstukken voor de populairste types radiatoren.
Als de mount niet past zijn er aparte conversie-ringen verkrijgbaar via de helpdesk. Bij ons paste één knop probleemloos en een andere niet. Via de helpdesk werden we vlug geholpen. Na het doorsturen van een foto van de bestaande knop, stuurde Tado ons via de post gratis een passend tussenstuk op waarmee we de knop probleemloos konden monteren.
De knoppen gebruiken twee AA-batterijen die volgens Tado één tot twee jaar meegaan. Bij één knop waren de batterijen echter al na amper een maand leeg en daarna opnieuw na een maand of drie. De app waarschuwt je tijdig wanneer je de batterijen moet vervangen (ook via e-mail). Na die waarschuwing heb je daarvoor nog ongeveer een week de tijd voor de knop uitvalt. Blijkbaar is er in sommige omstandigheden een bug die ervoor zorgt dat de batterijen abnormaal snel leeglopen. Tado meldt dat het hiervan op de hoogte is en het probleem aan het oplossen is. Overigens functioneerden de batterijen in de andere geteste knop wel normaal.

©PXimport
Besparing
De mobiele app stuurt je maandelijks een energiebesparingsrapport met de geschatte energiekosten die je bespaart door de slimme functies. Maar die cijfers zijn gebaseerd op gemiddelden uit een simulatiestudie van het Fraunhofer Instituut voor bouwfysica (Duitsland, 2013) en zeggen weinig over de werkelijke besparing in een individuele situatie.
Wel vind je in het rapport interessante statistieken over het aantal uren dat de geofencing actief was, hoe vaak Tado de verwarming aanstuurde volgens de weersvoorspelling, hoe vaak het slim schema actief was, hoe vaak de verwarming handmatig werd bediend en hoe vaak Tado een open raam detecteerde.
Tado toont ook een schatting van de besparing per ‘verwarmingsseizoen’. Volgens Tado bespaarde ik 25%. Maar hoeveel bespaarde ik nou echt?
Toevallig noteer ik al meer dan tien jaar het maandelijks gasverbruik op de testlocatie. Zo kon ik constateren dat het verbruik in de testperiode september 2017 tot mei 2018 inderdaad significant lager was: 25% onder het vijfjaargemiddelde en 9% onder het elfjaargemiddelde.
Andere factoren dan het gebruik van Tado hebben hierbij waarschijnlijk ook een rol gespeeld: een andere gezinssamenstelling, een andere boiler en (wellicht vooral) de klimaatverandering. Niettemin heeft Tado zo te zien invloed op het verbruik; hoevéél is moeilijk objectief vast te stellen, maar het lijkt in elk geval significant.
Conclusie
De slimme thermostaten en radiatorknoppen van Tado zijn betaalbaar, eenvoudig zelf te installeren en werken uitstekend. De helpdesk van Tado reageert snel en accuraat, ook in het Nederlands. Een mogelijk nadeeltje van het systeem is dat alle gezinsleden altijd hun smartphone bij zich moeten hebben om de besparende modi optimaal te laten werken.
Hoeveel je effectief bespaart, hangt af van te veel factoren om goed te kunnen testen, maar we vermoeden dat de meeste gebruikers de aankoopprijs van Tado binnen het jaar terugverdiend hebben met de besparing op hun verwarming. Sowieso is er ook het milieu-aspect: Tado zorgt er in elk geval voor dat je je huis zo weinig mogelijk onnodig verwarmt.
Het is natuurlijk wel zo dat productie, distributie en gebruik van het systeem als geheel zelf ook een geringe milieubelasting met zich meebrengt. Het effect daarvan laat zich echter niet meten en is waarschijnlijk te verwaarlozen in het grote geheel.
**Prijs:** € 199,99 **Website:** [tado.com](https://www.tado.com/nl//)
- Werkt met de meeste verwarmingssystemen
- Gebruiksvriendelijk
- Voldoet aan Europese privacyregelgeving
- Geen permanent display
- Niet mogelijk schema’s van zone naar zone te kopiëren
- Batterijen radiatorknoppen soms snel leeg









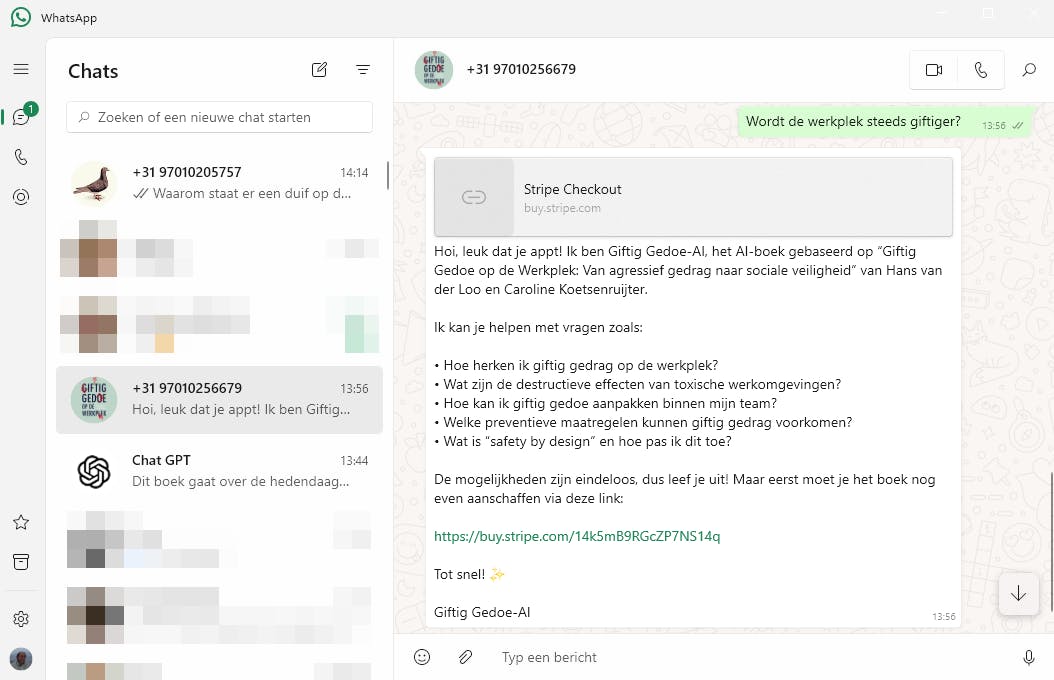 RAG-AI in de vorm van een WhatsApp-contactpersoon.
RAG-AI in de vorm van een WhatsApp-contactpersoon.








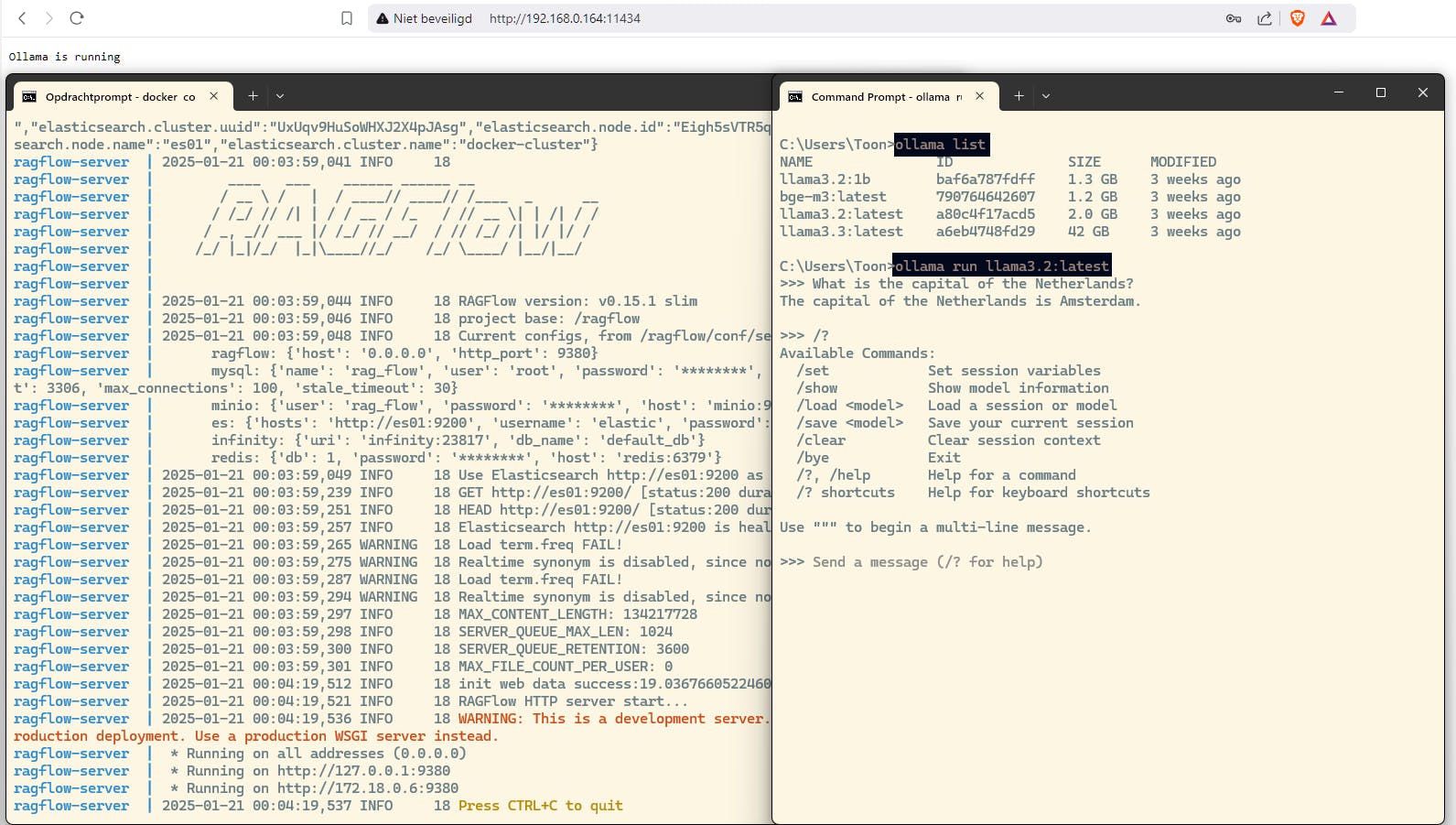 RAGflow met Ollama: een sterk duo, maar wel wat set-up- en configuratiewerk.
RAGflow met Ollama: een sterk duo, maar wel wat set-up- en configuratiewerk.









 Vraag aan ChatGPT om een leerplan op te stellen om je te helpen bij het programmeren.
Vraag aan ChatGPT om een leerplan op te stellen om je te helpen bij het programmeren.













 Via de console van Anthropic kun je een API-sleutel maken.
Via de console van Anthropic kun je een API-sleutel maken.












