OpenAI heeft het met ChatGPT het concept van een AI-chatbot populair gemaakt. Ook andere bedrijven bieden soortgelijke diensten aan. Daarnaast zijn er grote taalmodellen beschikbaar waarmee je zelf een chatbot kunt maken die op je eigen computer draait. Met Jan krijg je toegang tot al deze taalmodellen vanuit één interface.
Na het lezen van dit artikel weet je hoe je met Jan meerdere taalmodellen op je pc kunt beheren en hoe je ermee kunt werken:
- Installeer Jan
- Download de gewenste taalmodellen
- Ga ermee aan de slag:
- Vat pdf-documenten samen
- Laat beschrijven wat er op een afbeelding te zien is
- Laat je helpen bij programmeertaken
Ook bij een lokaal taalmodel is je prompt van belang: Prompt engineering: zo maak je precies het beeld dat je voor ogen hebt
Een groot taalmodel (Large Language Model of LLM) is een neuraal netwerk met miljarden parameters dat teksten kan genereren. Dit type algoritme kreeg brede bekendheid toen OpenAI in november 2022 de dienst ChatGPT lanceerde. Via deze webinterface kun je eenvoudig chatten met het taalmodel, en de antwoorden lijken vaak alsof ze van een mens komen.
Ook de concurrentie is niet stil blijven staan. Zo biedt het Franse bedrijf Mistral AI een online chatbot op basis van een eigen groot taalmodel. Daarnaast stellen bedrijven als Groq je in staat om allerlei grote taalmodellen in de cloud te draaien. Meta, het moederbedrijf van Facebook, bracht bovendien zijn groot taalmodel Llama uit in kleinere versies, die je zelfs op je eigen computer kunt draaien. Dat werd al snel gevolgd door een reeks andere grote en kleine taalmodellen van diverse bedrijven en onderzoeksinstellingen.
Het kan lastig zijn om al deze modellen uit te proberen: je moet dan allerlei verschillende webinterfaces gebruiken of van diverse locaties modellen downloaden. Jan biedt hiervoor een oplossing: je installeert deze opensourcesoftware op je eigen computer. Daarna verbind je via een API (Application Programming Interface) met een groot taalmodel in de cloud of download je een taalmodel van bijvoorbeeld Meta of Mistral op je eigen computer om het offline te gebruiken. En dat alles in één en dezelfde gebruikersinterface, waarin je eenvoudig tussen verschillende modellen kunt overschakelen.
1 Jan installeren
Jan is beschikbaar voor Windows, macOS (Intel- of Apple-processoren) en Linux. Op de downloadpagina vind je de verschillende versies. Als je lokaal grote taalmodellen wilt draaien, heb je een krachtige computer nodig. Onder Windows en Linux betekent dat een gpu van Nvidia of AMD met minstens 8 GB VRAM. Heb je een recente Mac, dan is een Apple M1-processor of nieuwer ook snel genoeg.
Nadat je Jan hebt gestart, schakel je eerst de hardwareversnelling in. Op Macs met een Apple-processor gebeurt dat automatisch, maar voor Windows en Linux dien je dat handmatig te doen. Raadpleeg de platformspecifieke installatie-instructies om de juiste drivers en andere nodige software te installeren. Voor een Nvidia-gpu open je in Jan de instellingen (het icoontje van het tandwiel linksonder) waar je klikt op Advanced Settings en GPU Acceleration inschakelt.
Voor de beste prestaties laat je Jan gebruikmaken van je gpu.
2 Lokaal AI-model draaien
Als je een groot taalmodel op je eigen computer wilt draaien, moet je dit eerst downloaden. Klik daarvoor in Jan linksboven op het icoontje met de vier vierkantjes. Dit brengt je naar de Hub, een verzameling van modellen die je kunt downloaden. Bij de modellen die je lokaal kunt draaien, staat de bestandsgrootte en een knop Download. Als er Recommended bij staat, draait het model goed op je hardware. Staat er de waarschuwing Slow on your device, dan komt dat bijvoorbeeld omdat je gpu te weinig VRAM heeft. Klik rechts naast de downloadknop voor extra uitleg over het model en klik op Download om het model op te slaan. Download bijvoorbeeld Mistral Instruct 7B Q4. Dat is een goed algemeen model dat al op een gpu met 8 GB VRAM draait.
Zodra het model is gedownload, verandert de downloadknop in Use. Klik erop om een nieuwe ‘thread’ te starten, een conversatie met het model. Dit kan ook door op de tekstballon linksboven te klikken. Voordat je een vraag typt in het tekstveld onderaan, raden we je aan aan de rechterkant naar enkele instellingen te kijken. In het tabblad Assistant kun je onder Instructions specifieke instructies geven die de antwoorden van de chatbot beïnvloeden, zoals de rol die het moet uitvoeren. In het tabblad Model kun je het taalmodel kiezen: naast de gedownloade modellen zijn ook de modellen die je online gebruikt via een API zichtbaar. Laat de andere instellingen voorlopig op hun standaardwaarden staan (zie het kader ‘Modelparameters’ voor de betekenis ervan). Nu kun je je vraag stellen. Jan zal eerst het taalmodel in het VRAM of RAM laden, wat even kan duren. Daarna verschijnt het antwoord redelijk snel. Vervolgvragen worden hierdoor ook sneller beantwoord.
Dankzij Jan kun je met alle mogelijke grote taalmodellen chatten.
Modelparameters
Jan laat je bij elk model diverse parameters aanpassen. In het tabblad Model heb je bijvoorbeeld Inference Parameters. Met de temperatuur stel je in hoe divers of voorspelbaar de antwoorden zijn en met Top P stel je in hoe gefocust of creatief het taalmodel is. Ook het maximumaantal tokens in het antwoord kun je instellen. Bij Engine Parameters kun je bij sommige modellen ook de contextlengte kiezen, wat de maximale lengte van de invoer bepaalt. Stel dat je korte vragen stelt, dan kun je de contextlengte korter houden, waardoor de berekening sneller gaat. Wil je daarentegen een langer document laten samenvatten, dan heb je een langere contextlengte nodig. Bij grote modellen is het soms nuttig om te kiezen hoeveel lagen van het neurale netwerk je op de gpu uitvoert; de rest wordt op je (tragere) cpu berekend. Jan doet standaard al zo veel mogelijk op je gpu.
//k1-jan-model-parameters.png//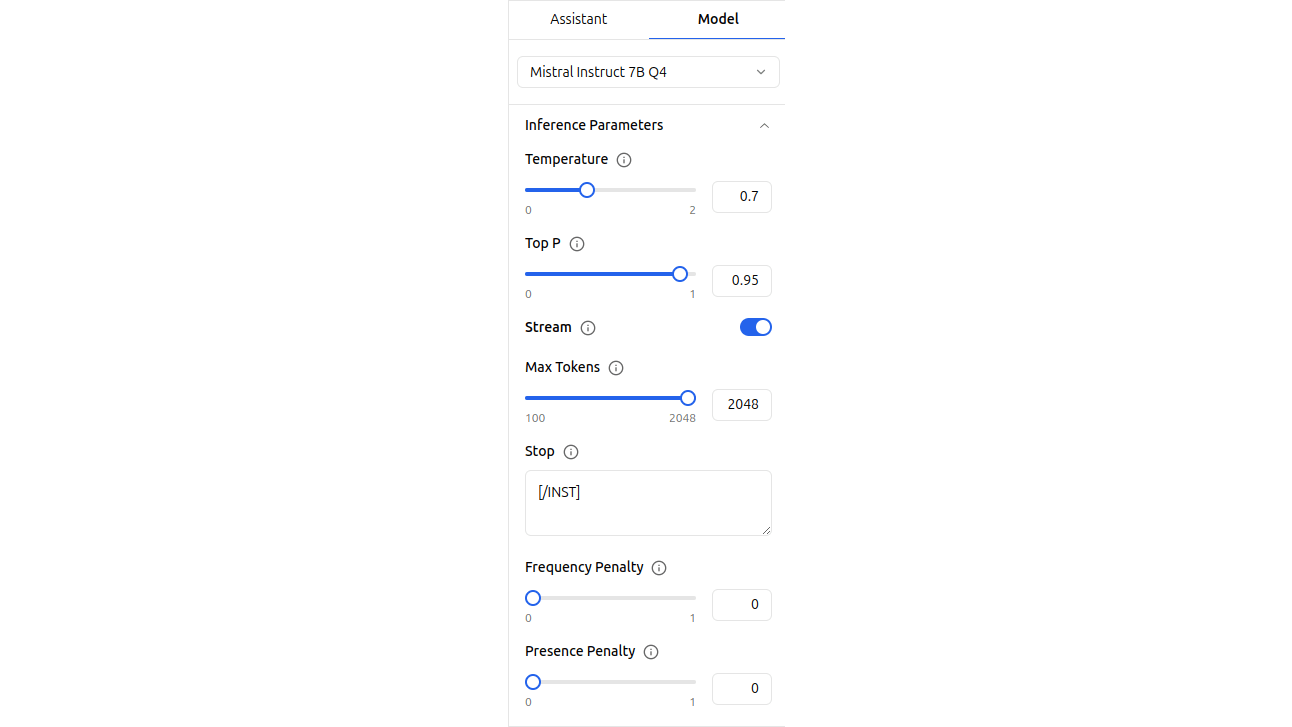 Jan laat toe om allerlei parameters van de taalmodellen aan te passen.
Jan laat toe om allerlei parameters van de taalmodellen aan te passen.
3 AI-model in de cloud draaien
Op dezelfde manier kun je modellen in de cloud draaien bij leveranciers als OpenAI, Anthropic, Mistral, Cohere en Groq. Hiervoor moet je eerst een API-sleutel voor de desbetreffende dienst instellen. Keer daarvoor terug naar de instellingen van Jan en klik bij Model Providers op de gewenste dienst. We illustreren dit met OpenAI. Bij API Key moet je een API-sleutel invullen, die je aanmaakt op de pagina API keys van je OpenAI-account. Klik daar op Create new secret key, geef je sleutel een naam en ken ze aan een project toe (er is een Default project). Klik dan op Create secret key. Kopieer nu onmiddellijk de gegenereerde sleutel en vul die in Jan in, want je krijgt die daarna nooit meer te zien.
Je kunt nu in de Hub van Jan naar OpenAI GPT 4o gaan en ernaast op Use klikken om een nieuw gesprek te starten. Of je klikt op de tekstballon linksboven, daarna op het icoontje met het potlood om een nieuwe thread aan te maken, om vervolgens aan de rechterkant bij Model OpenAI GPT 4o uit de lijst te selecteren. Cloudmodellen waar je geen toegang toe hebt omdat je nog geen API-sleutel hebt ingesteld, zijn grijs weergegeven. Je kunt tijdens het gesprek overigens op elk moment van model veranderen. Als je bijvoorbeeld merkt dat het model niet goed genoeg is voor je vraag, verander dan het model en klik op het knopje Regenerate bij het antwoord.
Creëer een API-sleutel om OpenAI’s grote taalmodellen in Jan te gebruiken.
4 Pdf-documenten samenvatten
Als je een model met lange contextlengte gebruikt, kun je in Jan ook pdf-documenten laten samenvatten of op andere manieren analyseren. Klik daarvoor eerst in de instellingen op Advanced Settings en schakel Experimental Mode in. Je threads tonen nu aan de rechterkant ook een tabblad Tools. Schakel daar Retrieval in.
Klik nu in je thread op het icoontje van de paperclip en kies Document. Selecteer het pdf-bestand dat je wilt analyseren. Nu kun je in het tekstveld onderaan vragen stellen aan het taalmodel over dit document. Als het lijkt alsof het taalmodel de informatie niet volledig heeft verwerkt, kun je experimenteren met de parameters in het tabblad Tools. Wees overigens altijd kritisch over de antwoorden. Vaak zit het taalmodel ernaast of antwoordt het onvolledig.
Als je de datasheet van de Raspberry Pi Pico W met GPT-4o bevraagt, zijn de antwoorden helaas onvolledig.
5 Multimodaal model
Sommige modellen kunnen niet alleen overweg met tekst, maar ook met afbeeldingen. Ze kunnen bijvoorbeeld een afbeelding die je hen voorlegt beschrijven of erover redeneren. We noemen dat multimodale modellen. Een voorbeeld hiervan is LLaVA (Large Language and Vision Assistant). In de Hub van Jan zijn enkele varianten te vinden, zoals LlaVa 7B, BakLlava 1 en LlaVa 13B Q4 (voor GPU’s met meer dan 8 GB VRAM).
Na je selectie kun je een afbeelding uploaden door in een gesprek op de paperclip klikken en voor Image te kiezen. Als het niet om een multimodaal model gaat, blijft Image grijs en kun je het niet selecteren. Daarna kun je vragen stellen over de afbeelding. Helaas bleek in onze test geen van de LLaVA-modellen uit Jans Hub te werken, ook niet met een LLaVA-model dat we van Hugging Face downloadden. Het is een van de redenen waarom de ontwikkelaars van Jan nog steeds waarschuwen dat hun programma in bètafase is.
6 Modellen van Hugging Face
Hugging Face is een Frans-Amerikaans bedrijf dat met zijn Model Hub een populaire website aanbiedt waar iedereen AI-modellen kan publiceren. Jan kan deze modellen van de Hugging Face Model Hub ook lokaal draaien, zolang ze in het formaat GGUF (GPT-Generated Unified Format) worden aangeboden. We illustreren dit met Granite Code 8B, een taalmodel van IBM dat is getraind om programmeertaken uit te voeren.
Als je binnen de Hugging Face Model Hub op de pagina van een GGUF-model rechtsboven op Use this model klikt en vervolgens op Jan, krijg je de vraag om de pagina in Jan te openen. Een andere manier is om in de Hub van Jan de url van het model te plakken. Jan toont je dan informatie over het model en biedt verschillende versies ter download aan. In ons voorbeeld is er maar één versie, maar vaak zijn er verschillende kwantisaties beschikbaar (zie het kader ‘Welke modelvariant kiezen?’). Klik op de downloadknop naast het gewenste model. Zodra het is gedownload, klik je op Use om een gesprek te beginnen.
Jan kan alle GGUF-taalmodellen van Hugging Face downloaden.
7 Modellen die programmeren
Taalmodellen zoals Granite Code, Codestral, Deepseek Coder en CodeNinja zijn gespecialiseerd in alles wat met programmeren te maken heeft. Vraag bijvoorbeeld om een Python-script dat met de bibliotheek Bleak scant naar bluetooth-apparaten in de buurt, en het taalmodel toont je de code hiervoor, inclusief uitleg en instructies om de benodigde bibliotheken te installeren.
Er zijn veel apparaten die met bluetooth werken
Draadloze koptelefoons bijvoorbeeld
De code zelf wordt in afzonderlijke kaders getoond, die je met een klik op het icoontje rechtsboven kopieert, zodat je de code in je eigen code-editor kunt plakken en uitproberen. Je kunt ook code invoeren in Jan en het model vragen om deze uit te leggen. Of geef code waarvan je weet dat er een fout in zit en vraag het model om de code te verbeteren. Vaak krijg je overigens code die niet werkt, of die een foutmelding geeft. Reageer dan met de foutmelding of vertel wat er fout gaat, en je krijgt een verbeterde versie. Na wat heen en weer communiceren krijg je vaak wel een bruikbaar resultaat.
Granite Code kan je helpen bij programmeertaken.
Welke modelvariant kiezen?
De meeste modellen komen in enkele varianten. De belangrijkste eigenschap is het aantal modelparameters, wat meestal in de miljarden ligt. Veelvoorkomende aantallen zijn 7B, 8B, 13B, 33B en 70B, waarbij de B voor miljard (billion in het Engels) staat. Een grotere versie behaalt doorgaans betere resultaten, maar je hardware moet het aankunnen. Idealiter kies je een model dat volledig in het VRAM van je gpu past: dan laadt Jan dit volledig in je gpu en worden de berekeningen ook volledig versneld door de gpu. Een 7B-model past doorgaans in een gpu met 8 GB VRAM, 13B in 16 GB VRAM en 33B in 32 GB VRAM. Draai je een model dat groter is dan je VRAM, dan wordt een deel van het neurale netwerk in het RAM geladen en door de cpu uitgevoerd, wat trager is. Modellen komen ook in verschillende kwantisaties. Veelvoorkomende aanduidingen zijn f16 (16 bits kommagetallen) en int4 (4 bits gehele getallen). Een int4-model is kleiner en werkt sneller dan hetzelfde model in de f16-versie, maar is minder nauwkeurig. Ook hebben de kwantisaties weleens aanduidingen als IQ3_XS, Q2_K_L en Q5_K_M. De exacte betekenis daarvan valt buiten het bestek van dit artikel, maar Q5_K_M biedt meestal een goed evenwicht tussen snelheid en nauwkeurigheid.
8 Extra cloudmodellen toevoegen
Er komen continu nieuwe taalmodellen bij, en Jan kan dat niet altijd direct volgen. Gelukkig kun je vaak met wat handmatige configuraties de nieuwe modellen toch nog aan de praat krijgen. We illustreren dit met GPT-4o mini, de goedkopere versie van GPT-4o die OpenAI aanbiedt. Tijdens het schrijven stond deze nog niet in Jans Hub, maar je kunt deze eenvoudig toevoegen. Jan slaat de configuratie van elk model op in een bestand in zijn datadirectory. Voor OpenAI’s GPT-4o is dat bijvoorbeeld in het bestand jan\models\gpt-4o\model.json in je persoonlijke map.
Om Jan toegang te geven tot GPT-4o mini, maak je een map gpt-4o-mini aan en kopieer je het bestand model.json van GPT-4o daarnaartoe. Pas nu in dit json-bestand het id aan van gpt-4o naar gpt-4o-mini, de naam van OpenAI GPT 4o naar OpenAI GPT 4o mini en het maximumaantal tokens van 4096 naar 16384. Deze waarde vind je op de website van OpenAI bij de eigenschappen van het model. Sla het bestand op, sluit Jan af en start het programma weer op. Daarna is het model in Jan beschikbaar.
Voeg het nieuwste model van OpenAI aan Jan toe.
9 Meer mogelijkheden
Jan biedt nog heel wat meer mogelijkheden. Zo kun je het programma als server draaien en functionaliteit van de taalmodellen aan andere programma’s aanbieden. In de code-editor Visual Studio Code kun je bijvoorbeeld met de extensie Continue hulp bij het programmeren krijgen. Continue communiceert dan op de achtergrond met een taalmodel dat Jan uitvoert.
Een ander interessant programma is Open Interpreter. Dit laat een groot taalmodel code genereren die dan op je computer wordt uitgevoerd. Je kunt bijvoorbeeld aan een taalmodel van Jan vragen om een bestand met data in te lezen en daar grafieken van te maken. Verder zullen er wellicht nog meer tools komen dan enkel het inlezen van pdf-bestanden.
Jan ondersteunt allerlei integraties om de grote taalmodellen toe te passen.






















